接續上一章的資料前處理後,今天要進入訓練模型的流程,讓我們繼續看下去~
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.metrics import categorical_crossentropy
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.preprocessing import image
from tensorflow.keras.models import Model
from tensorflow.keras.applications import imagenet_utils
from tensorflow.keras import layers,callbacks
from sklearn.metrics import confusion_matrix
首先我們要先把資料彙整起來,順便做一些增強處理,這邊小提一下,在做資料增強時一定要根據圖片的特性選擇適當的處理,否則會導致訓練不良,舉個例子:我們在做手寫數字辨識時,若做了水平翻轉的增強,那麼6跟9的資料就會搞混。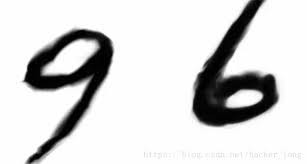
#Data_Augmentation & Data_Normalization
train_datagen = ImageDataGenerator(
rotation_range=0,
horizontal_flip=False,
vertical_flip=False,
width_shift_range=0.05,
height_shift_range=0.05,
preprocessing_function=tf.keras.applications.mobilenet.preprocess_input
)
valid_datagen = ImageDataGenerator(preprocessing_function=tf.keras.applications.mobilenet.preprocess_input)
因此我們這邊的增強只做簡單的水平、垂直平移,以及我們即將使用的MobileNets模型所提供的preprocessing_function,它會將所有值壓縮到[-1,1],驗證資料就不需要做增強,盡量讓資料保持原狀態即可。
這邊我們使用的是flow_from_dataframe的方法(DAY21有介紹),img_shape要根據模型的輸入限制去設定,batch_size則是根據自身設備去設定,最後用shuffle打亂資料。
img_shape = (224, 224)
batch_size = 16
train_generator = train_datagen.flow_from_dataframe(
dataframe=train,
directory=data_path,
x_col="ID",
y_col="Label",
target_size=img_shape,
batch_size=batch_size,
class_mode='categorical',
shuffle=True)
valid_generator = valid_datagen.flow_from_dataframe(
dataframe=valid,
directory=data_path,
x_col="ID",
y_col="Label",
target_size=img_shape,
batch_size=batch_size,
class_mode='categorical',
shuffle=True)
def num_steps_per_epoch(data_generator, batch_size):
if data_generator.n % batch_size==0:
return data_generator.n//batch_size
else:
return data_generator.n//batch_size + 1
train_steps = num_steps_per_epoch(train_generator, batch_size)
valid_steps = num_steps_per_epoch(valid_generator, batch_size)
套用imagenet的權重
model=tf.keras.applications.MobileNet(weights='imagenet',input_shape=(img_shape[0], img_shape[1], 3), include_top=False)
接著我們要更新輸出的類別數量
num_classes=6 #共六種類別
x = layers.GlobalAveragePooling2D()(model.output)
outputs = layers.Dense(num_classes, activation="softmax")(x)
model=Model(inputs=model.inputs,outputs=outputs)
Compile一些參數
lr=1e-4
model.compile(
loss="categorical_crossentropy",
metrics=["accuracy"],
optimizer = tf.keras.optimizers.Adam(lr)
)
這邊用到的套件功能是callbacks,它可以在模型訓練的過程中幫我們實現一些操作,這邊我們增加的功能有:
model_dir = './model-logs'
if not os.path.exists(model_dir):
os.makedirs(model_dir)
modelfiles = model_dir + '/{}-best-model.h5'.format('B0')
model_mckp = callbacks.ModelCheckpoint(modelfiles,
monitor='val_accuracy',
save_best_only=True)
earlystop = callbacks.EarlyStopping(monitor='val_loss',
patience=10,
verbose=1)
callbacks_list = [model_mckp, earlystop]
class_weights = {i:value for i, value in enumerate(class_weights)}
tf.config.list_physical_devices('GPU')
history=model.fit_generator(train_generator,steps_per_epoch=train_steps,
epochs=100,
validation_data=valid_generator,
validation_steps=valid_steps,
class_weight=class_weights,
callbacks=callbacks_list)
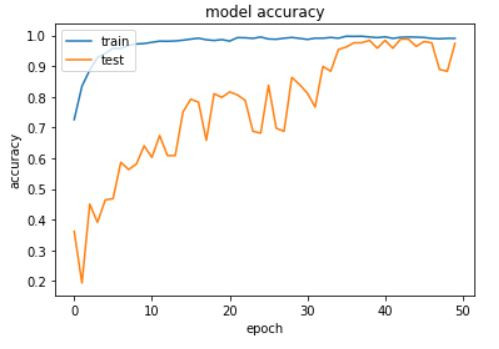
訓練完畢後我們可以用圖表來看一下訓練的狀況,分別畫出Accuracy以及Loss的圖,確定沒有過度擬合或欠擬和的狀況發生。
import matplotlib.pyplot as plt
#print(history.history.keys())
# summarize history for accuracy
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
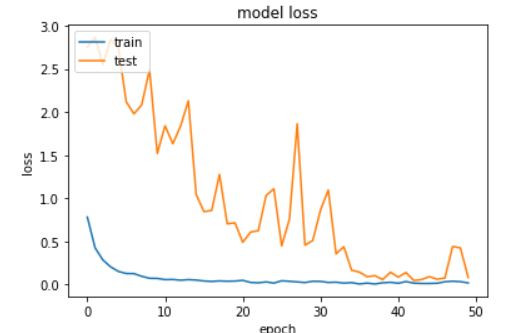
# summarize history for loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
我們自己挑了100張圖片出來放到一個資料夾,一樣要先將資料進行彙整。
data_path = "/content/drive/MyDrive/AOI"
test_list = pd.read_csv(os.path.join(data_path, "test.csv"), index_col=False)
data_path = "/content/drive/MyDrive/AOI/test_images"
test_datagen = ImageDataGenerator(preprocessing_function=tf.keras.applications.mobilenet.preprocess_input)
test_generator = test_datagen.flow_from_dataframe(
dataframe=test_list,
directory=data_path,
x_col="ID",
y_col="Label",
target_size=img_shape,
batch_size=batch_size,
class_mode='categorical',
shuffle=False)
test_steps = num_steps_per_epoch(test_generator, batch_size)
#預測出來會是機率,因此要經過轉換
y_test_predprob = model.predict(test_generator, steps=test_steps)
y_test_pred = y_test_predprob.argmax(-1)

from sklearn.metrics import accuracy_score, confusion_matrix
import seaborn as sns
print(f"accuracy_score: {accuracy_score(y_test, y_test_pred):.3f}")
confusion = confusion_matrix(y_test, y_test_pred)
plt.figure(figsize=(5, 5))
sns.heatmap(confusion_matrix(y_test, y_test_pred),
cmap="Blues", annot=True, fmt="d", cbar=False,
xticklabels=[0, 1], yticklabels=[0, 1])
plt.title("Confusion Matrix")
plt.show()
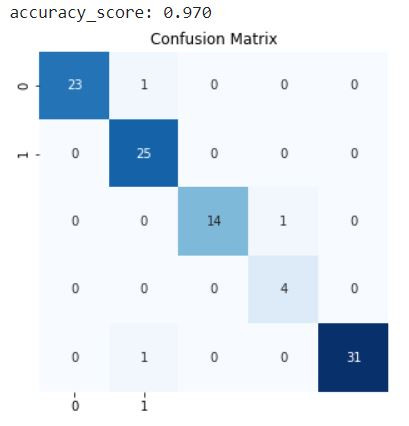
可以看到模型的表現還是挺不錯的,準確率高達0.97,這邊解釋一下為什麼混淆矩陣的大小是55,因為小編在抓圖片到測試資料集的時候漏抓了2類瑕疵(horizontal defect)的資料,實在是不好意思~
那麼模型的訓練就到這邊告一段落囉,我們將結果上傳到競賽平台後就可以得到系統計算的成績了,Accuracy可能會有些許的差距那是正常的,明天就是這個專案的最後一個章節了!我們會使用一些模型優化技巧來加強模型,大家盡請期待吧。


 iThome鐵人賽
iThome鐵人賽